9 min to read
문자열 처리의 해결사. 정규표현식을 알아보자 ②
정규표현식을 더욱 더 간결하게 사용할 수 있도록 도와주는 신택스 슈가에 대해서 알아봅시다.


이 포스트는 "정규식" 시리즈의 2번째 포스트 입니다.
-
문자열 처리의 해결사. 정규표현식을 알아보자 ①
텍스트 검색의 동반자 정규표현식의 기본 문법부터 차근차근 알아봅시다.
-
문자열 처리의 해결사. 정규표현식을 알아보자 ②
정규표현식을 더욱 더 간결하게 사용할 수 있도록 도와주는 신택스 슈가에 대해서 알아봅시다.
-
문자열 처리의 해결사. 정규표현식을 알아보자 ③
정규표현식에서 문자열 조작을 다뤄주는 캡처에 대해서 알아봅시다.
-
문자열 처리의 해결사. 정규표현식을 알아보자 ④
게으른 수량자인 겸허 수량자를 이용해, 캡쳐를 다루는 방법과 문자열 치환에 대해서 알아봅시다.
정규 표현식의 신택스 슈가(문법적 설탕)
앞 포스팅에서 설명한것이 정규표현식이 탄생했을 때의 연산의 전부지만, 지금은 많은 신택스 슈가(문법적 설탕)이 추가된 정규표현식을 우리는 사용하고 있습니다. 이를 통해서, 기본 3연산만 사용했을 때에는 복잡했던 패턴이지만, 이를 사용해서 조금 더 간결하고 보기 좋은 정규 표현식을 만들 수 있게 되었습니다. 기능적으로는 위의 3연산으로도 할 수 있는 것이지만, 가독성을 위해서 줄인 것이라고 생각하면 대강 맞는 설명입니다.
수량자(+, ?, {n,m})
*는 특정한 패턴을 0회 이상 반복하는 연산자라고 아까 배웠습니다. 정규 표현식을 작성할 때 “n회 반복”이라는 패턴은 자주 사용하고, *로만으로는 식이 깔끔하게 떨어지지 않는 경우도 있습니다. 사실, 지금 이 글을 읽는 여러분도 느꼈을 것입니다.
아까 소개했던 길이 1 이상의 숫자만으로 구성된 문자열을 찾는 식 부터가 같은 식을 두번이나 나열해야 하는 불편함을 가지고 있습니다. *가 0회 이상의 반복 연산이기 때문이죠. 이제, 이러한 패턴들을 조금이라도 더 깔끔하게 나타내는 연산자들을 하나씩 소개해보려고 합니다.
+(플러스 연산) : 1회 이상의 반복
+는 패턴의 1회 이상의 반복을 의미합니다. 예를 들어서, ab+c라는 정규 표현식은 ab*c와는 다르게, “ac”에는 일치하지 않고, “abc”, “abbbc” 등에 일치합니다. ‘r’이라는 표현식이 있다고 하면 (r)+와 r(r)*는 같은 패턴을 일치시키는 정규 표현식이기 때문에, +는 *의 신택스 슈가라고 할 수 있습니다.
?(물음표 연산) : 0회 또는 1회(존재 할 수도 있고, 아닐수도…)
?를 패턴 뒤에 붙이면 해당 패턴의 0회 또는 1회 반복을 의미합니다. 즉, ? 연산자가 적용된 패턴은, 있어도 되고, 없어도 되는 선택적인 패턴이 된다고 생각을 할 수 있고, 실제로 그런 용도로 쓰입니다.
예를 들어서, https?://kasterra.github.io라는 정규 표현식은, http로 시작하는 본 블로그의 주소나, https로 시작하는 본 블로그의 주소 모두에 일치합니다. s에만 물음표 연산이 적용되어 있으므로(머리속에 ?가 떠올랐다면, 위의 우선순위 표를 한번 참고하세요. ?도 반복 연산이기 때문에 접합 연산보다 우선순위가 높습니다) http와 https 둘 다에 일치하는 것입니다.
해당 패턴이 올지 안올지 확실하지 않은 상황에 활용할 수 있는 연산자 입니다.
범위 수량자({n,m}): n회부터 m회까지 반복
{n,m}은 패턴을 최소 n회부터 m회(\(n \le m\))까지 반복해서 표현하는 연산자 입니다. 반복 범위를 기술하기 때문에, 범위 지정 반복 제어 연산이라고도 하는데, 간단하게 범위 수량자라고도 합니다.
예를 들어서 x{1,5}라는 표현식은 x가 1회부터 5회까지 반복하는 것을 나타냅니다. 그러니까, 이를 선택 연산으로 풀어서 나타내면 아래의 표현식과 같게 됩니다.
x|xx|xxx|xxxx|xxxxx
x{3,3}처럼 최소 횟수와 최대 횟수를 같은 수로 지정하면, 정확히 해당 수만큼의 반복 횟수를 의미합니다. 이 경우는 x{3}으로 숫자 하나만 적어도 충분합니다.
그리고 더 똑똑한 기능도 있습니다. x{n,}처럼 최소 횟수만 치고, 최대횟수를 생략하면 “n 회 이상 반복”을 의미합니다.
범위 수량자를 사용할때 꼭 지켜야 할 사항
r{n,m}으로 식을 기술할 때, 반드시 \(n \le m\)을 만족해야 하고, {}안에는 숫자와 쉼표 외의 다른 문자가 있어서는 안됩니다(공백 포함).
이 사항을 어길 경우, 오작동을 일으키므로 주의해야 합니다.
.(임의의 한 문자)
일반 와일드카드 문자 검색에서도 임의의 한 문자를 나타내는 기호인 ?가 있습니다. 정규 표현식에도 해당 역할을 하는 메타 문자(특수한 용도로 쓰이기 위해 예약된 문자)가 있습니다. 모든 문자에 대해서 선택 연산을 한것과 동일하기에, 신택스 슈가입니다.
어떤 문자가 올지는 모르겠지만, 일단 모든 문자에 일치하게 만들고 싶을때 .을 사용합니다. 예를 들어서 r.*e라는 표현식은, ‘rare’나 ‘recognize’등 r로 시작해서 e로 끝나는 모든 문자열에 일치합니다.
주의 사항이 있는데, .는 모든문자에 일치하기 떄문에, ‘regular language’처럼 공백이 있는 문자열에도 일치하게 됩니다. 이 때문에, 의도하지 않은 동작이 이루어 질 수 있음에 유의해야 합니다.
이러한 동작을 방지하여, r로 시작하고 e로 끝나는 한 단어에만 일치하기 위해서는 후술할 문자 클래스를 활용하면 좋습니다.(a|b|……|z|A|B|…….Z| 이런식으로 쓰기에는 너무 손이 아프고, 읽기 좋지 않습니다. 그리고 혹시, 알파벳 하나를 빠뜨릴수도 있지요!)
문자 클래스
알파벳이나 숫자 등, 일련의 문자들을 패턴 내에 나타내고 싶을 때에 사용합니다. 아까 전에 길이 1 이상의 숫자 문자열을 (0|1|2|3|4|5|6|7|8|9)+로 길게 나타냈고, 좀 많이 길어 보였습니다. 그리고 직전 섹션에서는 알파벳 문자에만 일치하는 패턴이 필요합니다.
이러한 상황에서 우리를 도와줄 문법이 문자 클래스 입니다. 문자 클래스에서는 []안에 표현하고 싶은 문자들을 넣으면 됩니다. 예를 들어서, 0부터 9까지의 숫자를 나타내기 위해서는 [0123456789]로 나타낼 수 있습니다. 이것을 다음에 설명할 범위 지정을 이용하면, [0-9]로 더욱 세련된 형태로 작성할 수 있습니다.
범위 지정
문자 클래스의 []내부에서 -(대시, 하이픈)은 범위 지정기호로 인식됩니다. [a-z]처럼 하이픈 양쪽에 표현하고 싶은 문자 범위의 시작 문자와 끝 문자를 지정하면 됩니다.
아까 우리를 불편하게 했던, 길이 1 이상의 숫자로 된 문자열은 이제 [0-9]+라는 간단한 형태로 작성을 할 수 있게 되었습니다. 그리고, r로 시작해서 e로 끝나는 한 영단어에 대해서는 r[a-zA-Z]*e로 나타낼 수 있지요.
문자 클래스의 범위 지정은 ASCII 문자 코드의 순서를 따릅니다. 따라서, [a-Z]로 범위 지정을 하면, 알파벳 분자 외에도, ^나 _ 기호등 6개 기호에 일치하게 되는것이죠.
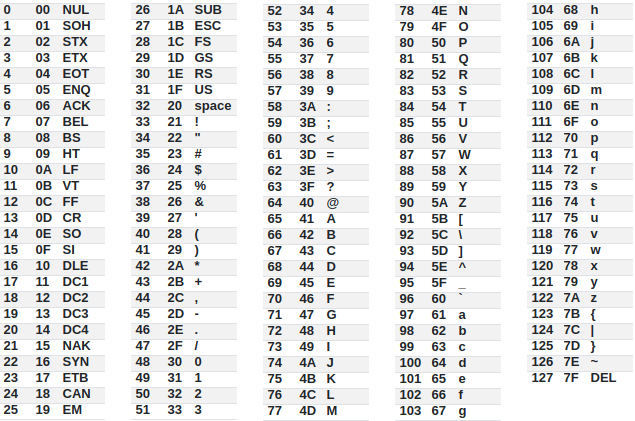
만약 - 문자 자체를 문자 클래스에서 일치하는 문자로 표현하고 싶으면, [-a-z]나 [a-z-]처럼 괄호 내의 앞이나 뒤에 적으면 범위 지정 연산자가 아니라 일반 문자로 인식됩니다.
부정
문자열 패턴을 지정할 때, 특정한 문자가 오지 않았으면 이라고 생각할 수도 있습니다. 이럴때, 문자 클래스 괄호 ([])내부에 ^문자를 선두에 넣으면, 일치하지 않기를 원하는 문자 집합을 표현할 수 있습니다.
예를 들어서, [^0-9A-Za-z]라고 하면, 숫자나 알파벳 외의 문자에 일치하는 정규 표현식이 됩니다. 문자 클래스의 부정을 사용하는 예를 하나 들자면, 인용 부호로 감싸진 1개의 문자열에 일치해야 하는 정규 표현식을 만들어야 할 때를 들 수 있습니다.
'This is a string'
단순히 생각하면 “'.*'을 사용하면 되지 않을까?” 하는 생각도 들 수 있지만, 이런 경우에는 쉼표로 분리된 2개의 문자열에 일치하는 경우도 발생합니다.
여기서 빨간색으로 표시된 부분은 위의 정규표헌식의 '에 일치하는 부분이고, 파란색으로 표시한 부분은 .*에 일치하는 부분 입니다.
우리가 바라던 바와 일치하지 않지요? 반면, 따옴표의 부정을 나타내는 [^']을 이용해서 '[^']'라는 정규 표현식을 이용하면, 작은 따옴표를 2개만 포함하는 문자열만을 찾게 되므로, 위의 상황에서는 ‘foo’와 ‘bar’에 각각 일치하게 될 것입니다. ‘troublesome 'case’와 같이, 이스케이프된 작은 따옴표를 포함하는 문자열도 약간의 수정만 통하면 간단히 표현할 수 있습니다. '([^']|\')*라는 표현식을 사용하면, ‘가 아닌것이나 \'에 일치하게 되어 이러한 경우도 올바르게 처리할 수 있게 됩니다.
이스케이프
숫자나 문자를 정규표현식에 처리하기 위해서는 아까 배운 문자 클래스 등을 활용하면 되지만, 스페이스나 탭 문자, 줄바꿈 문자 등의 보이지 않는 문자들을 표현하려면 어떻게 할까요? 스페이스나 탭 같은 우리 눈에 보이지 않는 문자들을 정규 표현식에 그대로 입력 한다면, 가독성이 상당히 떨어지는 무언가가 될 것임이 분명합니다.
이런 문자들을 표현하는 수단으로 (백슬래시, 한글 글자체에서는 원화(₩) 기호)를 이용하는 이스케이프 방식이 있습니다. C나 파이썬, java 등으로 프로그래밍을 경험해 봤다면, 줄바꿈 문자로 익숙할 \n같은 것을 생각하면 됩니다. 탭문자에는 \t가 할당되어 있는 식이죠. 이렇게 문자를 이용해서도 나타낼 수 있지만, \x00(16진수) \000(8진수) 등으로 아스키 코드를 기입할 수도 있습니다. 하단의 표는 일반적인 폰트에서는 공백으로 표시되는 문자들의 이스케이프를 정리한 표입니다.
| 이스케이프 | 의미 | 8진 기법 | 16진 기법 |
|---|---|---|---|
| \a | 경보문자 | \007 | \x07 |
| \f | 페이지 바꿈 | \014 | \x0c |
| \t | 탭(일반적인 수평 탭) | \011 | \x09 |
| \n | 줄바꿈 | \012 | \x0a |
| \r | 복귀 | \015 | \x0d |
| \v | 수직 탭 | \013 | \x0b |
이스케이프는 이런 눈에 보이지 않는 문자들도 표현할 수 있지만, 눈에 보이는 문자들 중에서도 자주 쓰이는 문자들을 간결하게 표현하는 용도로써도 사용되기도 합니다. 예를 들어 10진수 숫자들에 쓰이는 숫자들인 [0-9]는 \d(decimal의 d)로 표현되고, [0-9a-zA-Z_]는 \w로 표현되는 경우가 많습니다. 또한 이 방식에서는 대문자로는 해당 집합의 부정형을 나타내는데, 예를 들자면 \D는 \d의 반대로 [^0-9]를 의미하는 식인 것입니다.
정규 표현식은 하나의 표준이 있다기 보다는, 대강의 표준같은 무언가가 있고, 각 엔진별로 사용법이 다른 경우가 많아(혹자들은 이를 ‘사투리’라고도 합니다), 사용할 때 마다 적당한 구글링으로 찾아보는것을 권장합니다. 아래는 그래도, 많은 정규표현식에서 쓰이는 문자 클래스의 이스케이프 형태들을 정리한 표 입니다.
| 이스케이프 | 의미 | 문자 클래스 |
|---|---|---|
| \d | 숫자 | [0-9] |
| \D | 숫자 외 | [^0-9] |
| \w | 문자열 기호 | [A-Za-z0-9_] |
| \W | 문자열 기호 외 | [^A-Za-z0-9_] |
| \s | 스페이스 문자(공백 문자) | [\t\n\f\r] |
| \S | 스페이스 문자 외 | [^\t\n\f\r] |
메타 문자를 이스케이프
이스케이프 에는 특수한 용도로 사용되는 메타 문자들을, 해당 문자 그 자체, 즉 리터럴로 인식 시키는 기능 또한 존재합니다. 이것도 C 계열의 언어로 프로그래밍을 해봤다면 익숙할 그 용법입니다.
예를 들어서, a*b라는 표현식은 ‘ab’나 ‘aaab’에는 일치하지만, ‘a*b’ 라는 문자열에는 일치하지 않습니다. ‘a*b’라는 문자열 자체에만 일치하기 위해서는 a\*b 처럼 메타문자인 *를 이스케이프 시켜줘야 합니다. 이런 식으로 특수한 문자들을 그 문자 그 자체인 리터럴로 사용하려면, 앞에 \문자를 붙여서 이스케이프 해주면 됩니다.
앵커
이때까지 알아본 메타 문자들은 특정한 문자나 문자열에 일치하는 문자였지만, 앵커는 문자열이 아닌, “위치”에 일치하는 특이한 메타 문자입니다. ‘길이가 0인 문자’에 일치한다고 생각 할 수도 있어서, 제로 넓이 어설션(zero-width assertion)이라고도 하기도 한다네요.
앵커로 표현할 수 있는 위치에는, 여러 종류가 있으며, 특정한 문자나 이스케이프를 이용합니다. 하단의 표는, 주로 사용되는 앵커의 종류입니다.
| 앵커 | 위치 |
|---|---|
| ^ | 행 처음 |
| $ | 행 끝 |
| \A | 텍스트 선두 |
| \b | 문자열 사이 |
| \B | 문자열 사이 외 |
| \z | 텍스트 끝 |
보다 더 확실한 이해를 위해서, ‘문자열과 문자열 사이’라는 위치에 일치하는 \b의 예를 살펴보도록 하겠습니다.
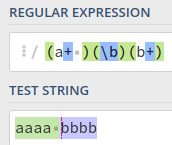
(a+ )(\b)(b+) 정규 표현식 일치 결과위의 결과에서 초록색으로 되어 있는것은 (a+ )(+뒤에 공백이 있음에 유의)에 일치한 것이고, 파란색으로 되있는 부분은 (b+)(이것은 공백이 없다)에 일치한 부분입니다. 그럼 \b는 어디에 일치하냐고요? 위의 그림을 잘 보면, 빨간색 점선이 있을 것입니다. 이게 \b가 일치하는 부분, 즉 문자가 아닌 단어의 경계라는 위치에 일치하는 모습을 볼 수 있습니다.
이것 만으로는, 왜 이런 쓸데 없는걸 만들었는가 생각할 수도 있지만, 다음 포스팅에서 설명할, 정규 표현식을 이용한 문자열의 치환에서는 정말 강력하게 작용하는 요소 중 하나입니다. 이 부분이 지금 당장 이해가 되지 않는다면, 다음 포스팅을 읽고, 잠깐 갸우뚱 해질 때, 다시 확인해 봐도 나쁘지 않습니다.
참고한 자료
다양한 언어로 배우는 정규표현식 최신 엔진 구현과 이론적 배경을 배우다(신야 료마 , 스즈키 유스케 , 타카타 켄 지음)